Attaching Datastores
Datastores can be mounted to both Runs and Sessions. Below are examples on how to do that.
Runs
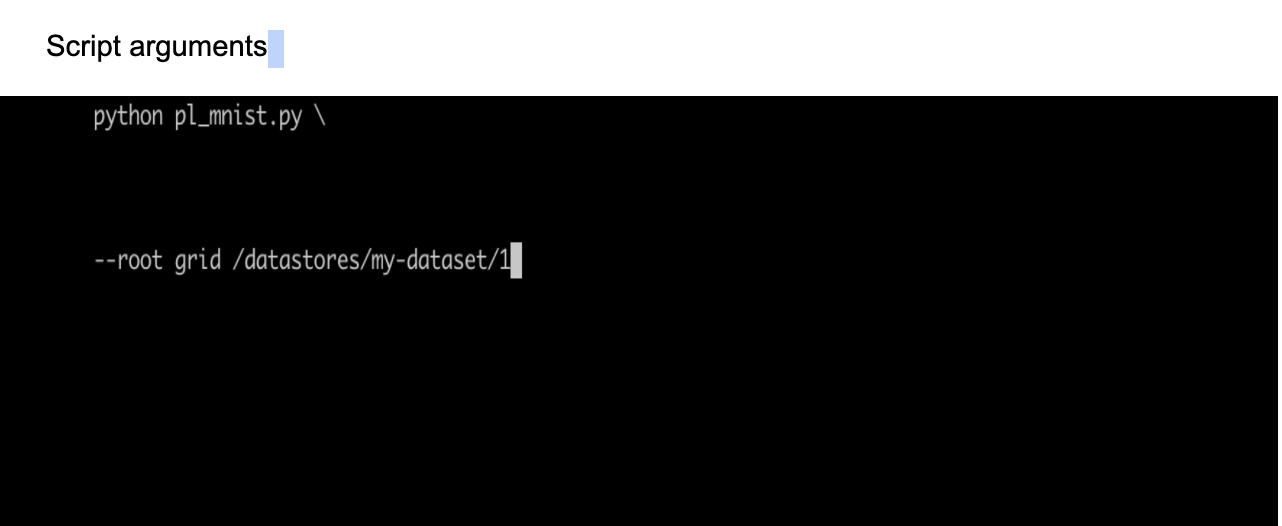
You can mount a datastore to a run to make your experiments run faster! By default, the datastore is mounted at /datastores in a Session or Run. When attaching datastores to a run, take note of the path your script uses. For example if your script takes an argument my_data_path and you want to mount the cats datastore:
grid run --datastore_name cats --datastore_version 1 -- main.py --my_data_path /datastores/cats
note
We provide a working example showcasing this functionality on the Basic Runs Creation page.
Sessions
This video shows how we attach an ImageNet Datastore to a Session.
In Sessions, datastores are mounted to /datastores. However, since Juypyter notebooks use
/home/jovyan as the default working directory, we provide a symlink from
/home/jovyan/datastores to /datastores/ so you can access your datastore easily upon
opening up a Session.
Once in the Session, view the data with:
cd /datastores
ls
Datastore paths
Say you have a dataset with this structure:
my_dataset /
train/
...
val/
...
On your local machine, you call the script like this:
python main.py --root my_dataset/
Your script uses the dataset like this:
args.add_argument('-root')
root = args.parse_args()
train = load(root + 'train')
val = load(root + 'val')
When you upload a datastore to Grid:
grid datastore create my_dataset
It is available under this structure:
train/
...
val/
...
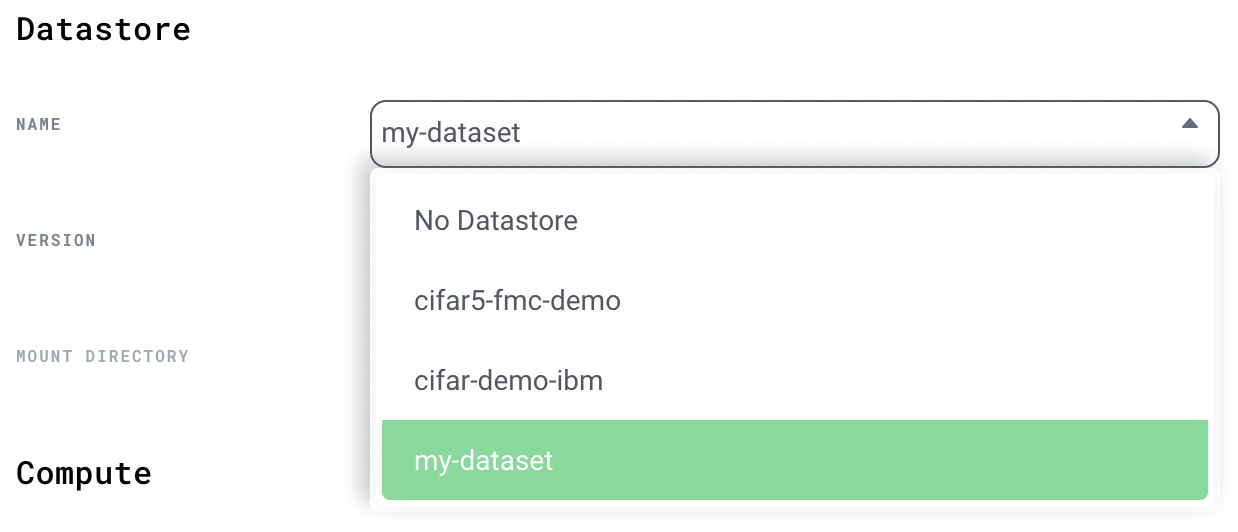
To run on this datastore, select the datastore from the dropdown.
Now pass the name of the datastore to your command.